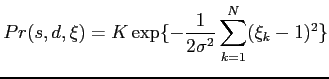The prior distribution is used to bias the global transformations (changes in translation and scale) and local deformations that can be applied to a prototype template. In contrast to the work of Jain et al. [80], rotation is not taken into account as we assume that this is represented in the probabilistic template.
![]() denotes a deformation of the original template
denotes a deformation of the original template
![]() . This deformation is performed by locally deforming the
template by a set of parameters
. This deformation is performed by locally deforming the
template by a set of parameters ![]() , scaling the local
deformation by a factor of
, scaling the local
deformation by a factor of ![]() , and translating the scaled version
along the
, and translating the scaled version
along the ![]() and
and ![]() directions by an amount
directions by an amount
![]() .
.
Assuming that translations and scale sizes have equal
probability4.1, and using Eq. ![]() for the
deformation probability, the prior distribution results in:
for the
deformation probability, the prior distribution results in:
where ![]() is a normalization factor. Intuitively, a
deformed template with a geometric shape similar to the prototype
template is favoured, regardless of its size and location in the
image.
is a normalization factor. Intuitively, a
deformed template with a geometric shape similar to the prototype
template is favoured, regardless of its size and location in the
image.