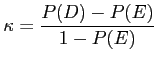A confusion matrix is a visualization tool commonly used in supervised machine learning. It contains information about actual and predicted classifications by a classification system. Usually, each column of the matrix represents the instances of the predicted class, while each row represents the instances of the actual class.
The confusion matrix is useful to evaluate the performance of a classifier, showing the number per class of well classified and mislabeled instances. Moreover, it is easy to see if the automatic system is confusing two or more classes (mislabeling one class as another).
An example of confusion matrix is shown in
Table ![]() (a). Is easy to see, for instance, that
(a). Is easy to see, for instance, that ![]() instances of Class A are correctly predicted as Class A and, in
contrast,
instances of Class A are correctly predicted as Class A and, in
contrast, ![]() and
and ![]() instances of Class A are misclassified as
Class B and Class C, respectively. The same can be done for the
other classes. The numerical evaluation of a confusion matrix is
commonly computed as the percentage of correctly classified
instances. For instance, in Table
instances of Class A are misclassified as
Class B and Class C, respectively. The same can be done for the
other classes. The numerical evaluation of a confusion matrix is
commonly computed as the percentage of correctly classified
instances. For instance, in Table ![]() (a) an agreement
of
(a) an agreement
of ![]() is achieved.
is achieved.
Another measure which can be extracted from a confusion matrix is
the kappa (![]() ) coefficient [34,51], which is
a popular measure to estimate agreement in categorical data. The
motivation of this measure is to extract from the correctly
classified percentage the actual percentage expected by chance.
Thus, this coefficient is calculated as:
) coefficient [34,51], which is
a popular measure to estimate agreement in categorical data. The
motivation of this measure is to extract from the correctly
classified percentage the actual percentage expected by chance.
Thus, this coefficient is calculated as:
Thus, following the example, Table ![]() (b) shows the
classification of the instances as expected by mere chance, given
the observed marginal totals. Using the above formula
(b) shows the
classification of the instances as expected by mere chance, given
the observed marginal totals. Using the above formula
![]() , which looking at Table
, which looking at Table ![]() is in the
moderate agreement. However, what means kappa? Looking at the
example, note that of the correctly classified
is in the
moderate agreement. However, what means kappa? Looking at the
example, note that of the correctly classified ![]() instances of
(a) (the sum of the diagonal values),
instances of
(a) (the sum of the diagonal values), ![]() of them were in fact
expected by chance, thus showing that the classifier agrees in
of them were in fact
expected by chance, thus showing that the classifier agrees in
![]() more cases. Similarly, the number of mislabeled instances
expected by chance is
more cases. Similarly, the number of mislabeled instances
expected by chance is ![]() . The coefficient
. The coefficient ![]() is
simply this ratio (
is
simply this ratio (![]() ), which can be translate as ``of all
the
), which can be translate as ``of all
the ![]() items that would have mislabeled by chance, a total of
items that would have mislabeled by chance, a total of
![]() are in fact correctly classified".
are in fact correctly classified".