Mineria de dades per tasques de classificació¶
Return to Artificial Intelligence Lab Notebooks
Autor: Pablo Gay, Beatriz López
Data: 2017-03-20
# Aquesta linia fa que les grafiques surtin a la llibreta, executar pero no tocar
%matplotlib inline
# Llibreria auxiliar
import numpy
Material i entorn de treball¶
- Descarregar l'instal·lador de l'entorn de treball Jupyter/WinPython
- Executa i espera la descompressió de l'instal·lador.
- Instal·lar deixant totes les opcions predeterminades.
- Per defecte el directori d'instal·lació serà el mateix que el directori de descàrrega.
- Obrir la carpeta on acabeu d'instal·lar Jupyter/WinPython, després el directori
notebooks. - Descarregeu i descomprimiu el contingut d'aquesta pràctica aquí.
- Des del directori d'instal·lació, executar el fitxer
Jupyter Notebook.exe.
Conceptes que assolireu:¶
- Familiarització amb els problemes clàssics d'aprenentatge.
- Coneixement de les bases de dades públiques del repositori UCI
- Utilització de les llibreries estadistiques i d'aprenentatge automàtic seaborn i sklearn.
- Procés de tractament de dades des de l'origen fins a l'aplicació de models d'aprenentatge.
Introducció¶
La tecnologia ens permet capturar i emmagatzemar grans quantitats de dades. Trobar patrons, tendències, i anomalies en aquests conjunts de dades, i resumir-les en un model quantitatiu simple, és un dels grans reptes de l’era de la informació – convertir dades en informació, i convertir informació en coneixement.
La mineria de dades té com a objectiu l’extracció del coneixement implícit, no conegut, i potencialment útil de les dades. L’aprenentatge automàtic proporciona les bases tecnològiques, algorismes, per a dur a terme la mineria de dades.
No existeix un mètode d’aprenentatge automàtic per a tots els problemes de mineria de dades. Els mètodes solen agrupar-se per la tasca objectiu de l’aprenentatge: agregació, classificació, predicció, explicació, descripció. En aquest laboratori ens centrarem en la tasca de classificació, i en un conjunt d’algorismes que construeixen arbres de decisió (models).
Cal recordar que els mètodes d’aprenentatge habiliten la cadena de descobriment del coneixement, però també hi ha d’altres passos necessaris com la selecció, preparació, i transformació de dades, i la posterior interpretació i avaluació dels resultats (veure Figura 1). En aquesta pràctica treballarem els primers conceptes, mentre que el darrer es tractarà en la pràctica següent.
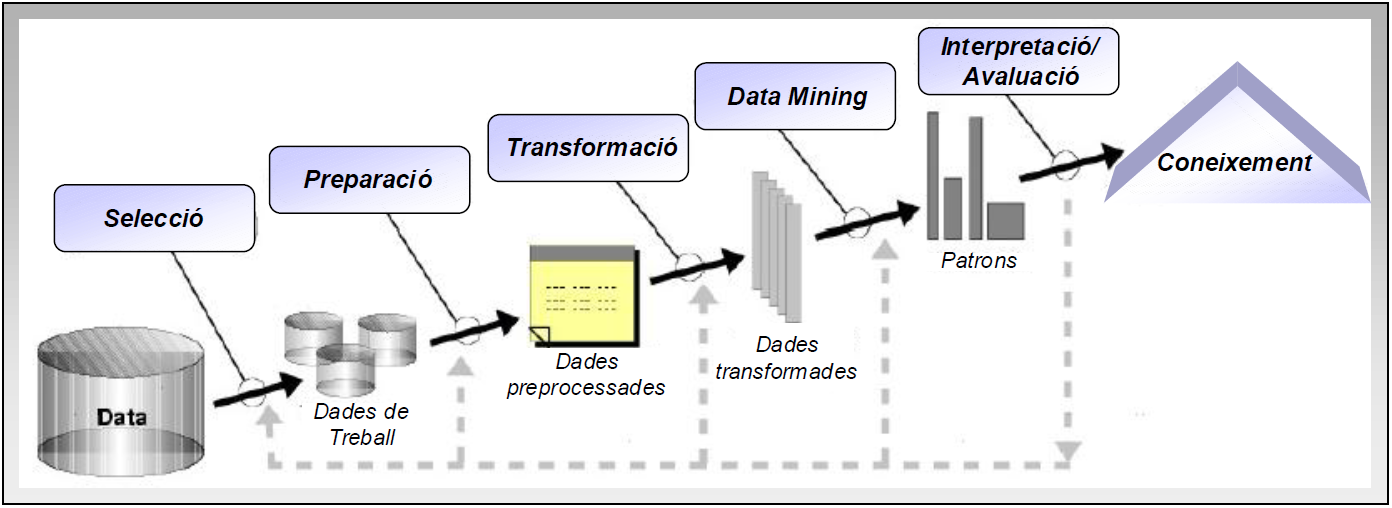 Figura 1. Descobriment del coneixement.
Figura 1. Descobriment del coneixement.
Problema: detecció d'esquerdes en cilindres d'impressió¶
La impressió per rotogravat consisteix en girar una superfície cromada, sobre un cilindre gravat en un bany de tinta, l’eliminació de l’excés de tinta, i la pressió sobre un paper continu sobre la imatge entintada en un rodet de goma ( veure Figura 2). Un cop el treball s’imprimeix, la imatge es retira del cilindre i es passa a imprimir el següent treball. A vegades, apareixen unes esquerdes o solcs en el cilindre que fa que el procés d’impressió no tingui la qualitat esperada. Aquestes esquerdes no estan presents en l’inici del procés d’impressió, però un cop que apareixen, cal parar la màquina. A continuació, un tècnic elimina l’esquerda mitjançant algun procés de poliment, o portant el cilindre a un departament especial de la planta per recobrir-lo de crom.
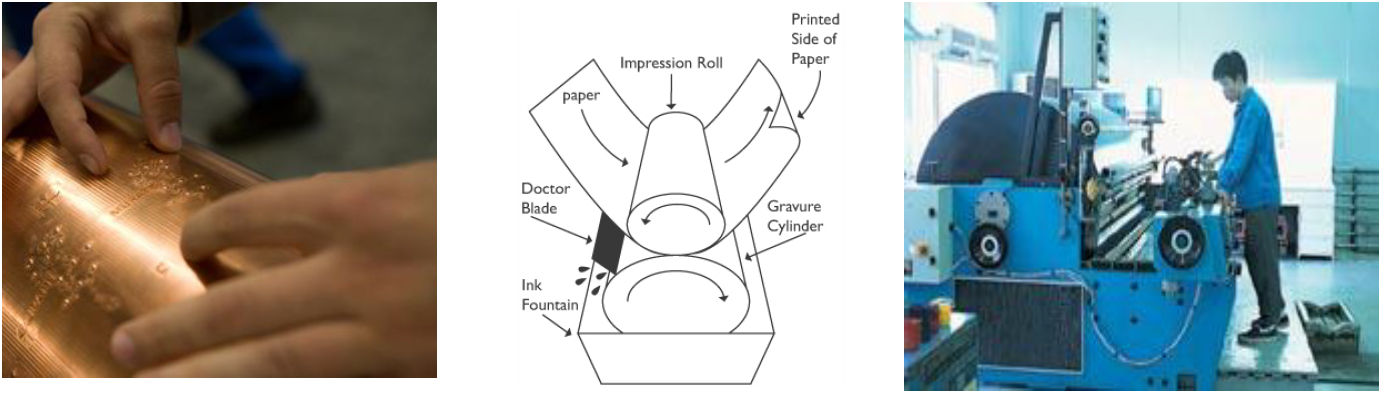 Figura 2. Esquerra: Detall del procés. Centre del procés d’impressió. Dreta: Exemple de màquina
Figura 2. Esquerra: Detall del procés. Centre del procés d’impressió. Dreta: Exemple de màquina
Aquest procés de reparació pot trigar una mitjana de 1,5 hores (mínim 30 minuts, i fins a 6 hores). Durant aquest temps, de 3 a 10 persones poden estar aturats, segons el que s’estigui imprimint, i la despesa generada s’ha de carregar a temps de retards. Molts cops, això comporta la programació d’hores extraordinàries en caps de setmana.
Els fabricants de impressores de fotogravat estan cercant sempre màquines que vagin més ràpides per millorar els ratis de producció i minimitzar els retards. Però mentre que s’estan aconseguint màquines més ràpides, els tema dels retards degut a les esquerdes és un tema pendent de solucionar. Quan es coneixen les causes de les esquerdes, els experts poden aplicar sensors i mitigar els seus efectes, intentant una diagnosi en temps real dels dispositius involucrats. Tanmateix, els experts coneixen ben poc de les causes de les esquerdes. En aquesta situació, els mètodes de mineria de dades permeten obtenir un model que permeti donar suport als operaris.
En aquesta pràctica utilitzarem dades provinents d’una màquina de rotogravat, i intentarem construir un arbre de decisió per classificar l’estat de la màquina: band (el cilindre té una esquerda), no band (el cilindre no té una esquerda).
Dades¶
Les dades estan disponibles en un repositori públic de dades anomenat UCI a la URL següent: http://archive.ics.uci.edu/ml/datasets/Cylinder+Bands
A l’adreça hi trobareu una descripció de les dades del problema a resoldre. També trobeu dos arxius:
- bands.names que conté la descripció de les dades.
- bands.data que conté les dades.
Llegiu acuradament la descripció que proporcionen els enllaços suggerits. bands.names ens descriu el dataset, des de els seus creadors, els usos que ha tingut en l'àmbit científic o fins i tot característiques de les dades.
Exercici 1: Comenta la descripció de les dades (número d’instàncies, quins atributs té i de quin tipus són, si té valors perduts, etc.)
Per agilitzar la pràctica, farem servir el fitxer bands.csv (el podeu descarregar aquí). L'extensió CSV fa referència a que els valors continguts en el document estan separats per comes (Coma Separated Values). A més a més, s'ha afegit una primera línia amb el nom de les columnes. Podeu trobar aquest fitxer al costat d'aquesta llibreta dins de la carpeta de notebooks.
Anàlisi estadístic¶
Abans de començar a aplicar mètodes d'aprenentatge automàtic és necessari analitzar les dades per tal de comprovar si existeixen errors, valors buits, tendències, etc. Això ho farem amb les següents llibreries:
- pandas: És una llibreria que permet carregar i manipular dades.
- matplotlib: Aquesta llibreria serveix per mostrar gràfics.
- seaborn: Llibreria encarregada de fer gràfics estadístics amb l'ajuda de matplotlib.
El fet d'analitzar les dades en permetrà també poder fer una estimació de quins algorismes d'aprenentatge automàtic ens poden ser útils. Ara, nostre primer pas serà carregar el fitxer bands.csv amb les dades. Això ho farem amb la funció read_csv() de pandas. Com a paràmetres li passarem on es troba el fitxer i quin és el caràcter que representa els valors perduts, en aquest cas ?.
# Carreguem la llibreria
import pandas
# Carreguem les dades
bands = pandas.read_csv('./bands.csv', na_values=['?'])
Per comprovar si les dades s'han carregat bé, podem fer servir la comanda head() que ens ensenyarà les 5 primeres línies.
bands.head()
Exercici 2: Amb les dades mostrades podeu indicar com es representen els valors perduts?
Els valors perduts ens impedeixen analitzar les dades correctament. Existeixen diversos mètodes per tractar-los, com per exemple substituir-los pel valor mig de la columna, però l'alternativa més simple si tenim moltes dades és eliminar els registres directament. Això es fa mitjançant la comanda dropna() com veieu a continuació.
# Eliminem registres amb valors perduts
bands = bands.dropna()
El següent pas consisteix en explorar les dades. Podem obtenir un resum estadístic ràpid mitjançant la comanda describe().
bands.describe()
Com podeu observar, els atributs tenen magnituds diferents: press speed te una mitjana de 1851 mentre que roughness la te de 0.71. Aquesta gran diferència farà que qualsevol algorisme d'aprenentatge automàtic consideri un canvi de 8 unitats a press speed (0.4% de variació) més important que un de 0.5 a roughness (70% de variació). Per tant el següent pas consisteix en re-escalar les dades.
Aquest procés és útil per quantificar la similitud de qualsevol parell de mostres. Farem servir les llibreries de pre-processat de dades de sklearn anomenades MinMaxScaler, concretament la funció fit_transform(), que modificarà tots els valors per a estar dins del rang [0,1].
# Carreguem la llibreria
from sklearn.preprocessing import MinMaxScaler
# Normalitzem totes les columnes excepte la ùltima (-1) ja que és de tipus text i conté la classe.
min_max_scaler = MinMaxScaler()
bands[bands.columns[:-1]] = min_max_scaler.fit_transform(bands[bands.columns[:-1]])
Exercici 3:Torneu a fer servir la funció
describe()i comenteu el canvi de les dades
Amb aquest resum estadístic ens podem fer una idea dels rangs que poden prendre els atributs, però per poder esbrinar si els atributs de les diferents mostres tenen correlacions que ens puguin ser útils podem representar-los dos a dos. Això ho farem mitjançant la llibreria matplotlib que serveix per mostrar gràfics i la llibreria seaborn que s'encarrega de construir gràfics estadístics mitjançant matplotlib. Concretament el gràfic per comparar atributs dos a dos es crea amb la comanda pairplot() donant com a paràmetres les dades i quina és la columna que representa la classe. A més a més, a la diagonal ens mostrarà l'histograma de l'atribut.
# Carreguem les llibreries
import matplotlib.pyplot as plt
import seaborn
# Mostrem el grafic dos a dos
seaborn.pairplot(bands, hue='band type')
Com que tenim molts atributs, és difícil veure si hi han atributs correlacionats. Els gràfics estan ordenats d’amunt a avall i de dreta a esquerra en el mateix ordre que les columnes mostrades amb la funció describe(). Per veure millorels gràfics, a la següent cel·la de codi poseu el nom de les columnes en el format especificat.
#columnes = ['NOMCOLUMNA1', 'NOMCOLUMNA2', 'NOMCOLUMNA3']
# Per exemple:
columnes = ['proof cut', 'viscosity']
seaborn.pairplot(bands, hue='band type', vars=columnes)
Exercici 4: Indiqueu el nom de les columnes (tantes com creieu) que poden estar correlacionades i comenteu el seu comportament. Raoneu si hi ha cap atribut que pugui facilitar la classificació.
Aprenentatge automàtic: arbres de decisió¶
Els arbres de decisió son mètodes d’aprenentatge automàtic supervisats que comunament es fan servir per problemes de classificació. L'objectiu és crear un model que predigui el valor de l'atribut a classificar mitjançant senzilles regles extretes dels altres atributs.
Alguns dels avantatges dels arbres de decisió són:
- Requereixen poca preparació de les dades.
- El cost computacional es logarítmic en relació al mida del conjunt de dades d'entrenament.
- Són una caixa blanca. Una determinada classificació pot ser explicada fent servir la lògica boolean de les regles.
Per poder entrenar un arbre de decisió caldrà separar les dades originals en dos: un conjunt de dades amb tots els atributs excepte la classe que es vol predir i un altre conjunt només amb la classe. D'aquesta forma per una banda tindrem totes les mostres d'entrada i per l'altre la classe de sortida que desitgem que el nostre algorisme retorni per cada una de les mostres.
Això ho aconseguirem amb les següents comandes:
# Agafem totes les dades excepte la ultima que representa la classe
entrades = bands[bands.columns[:-1]]
# Agafem la classe unicamen
classes = bands['band type'].values
Per poder validar que un model funciona, una pràctica general es reservar un petit conjunt de les dades originals per fer proves i fer servir la resta per entrenar el model. Això es coneix com a train/test split. Les llibreries de selecció de models de sklearn tenen la funció train_test_split(), on per paràmetres podem especificar quines son les entrades, les classes in quin percentatge d’entrenament volem. En aquest cas seleccionarem aleatòriament un 75% de les dades per crear i entrenar el model i el 25% per provar el seu poder de classificació.
from sklearn.model_selection import train_test_split
(entrades_train,
entrades_test,
classes_train,
classes_test) = train_test_split(entrades, classes, train_size=0.75)
Ara que tenim les mostres i classes d'entrenament i de proves separades podem crear el nostre classificador entrenar-lo i provar la seva precisió. Els arbres de classificació DecisionTreeClassifier es troben al a llibreria d'arbres de sklearn. La següent cel·la de codi ensenya com crear-ne un fent servir l'entropia com a criteri.
from sklearn.tree import DecisionTreeClassifier
decision_tree_classifier = DecisionTreeClassifier(criterion='entropy')
Amb el model ja creat, només resta començar l'entrenament. Això ho podem fer amb la comanda fit() del model passant com a paràmetres les mostres d'entrenament i les seves classes associades.
decision_tree_classifier.fit(entrades_train, classes_train)
Per tal de comprovar com de bé funciona l'arbre de decisió que heu entrenat, farem servir la comanda score(). És molt semblant a la comanda fit() però en aquest cas en comtes de crear el sistema de regles de l'arbre, només farà servir les ja existents amb el conjunt de mostres d'entrenament. També proporcionarem les classes de les mostres de proba per tal de comprovar com d'acurat és.
decision_tree_classifier.score(entrades_test, classes_test)
Exercici 5: Quina és la precisió del vostre arbre? Compareu aquest resultat amb el que sortiria si a la funció
score()li passéssiu un altre cop les dades d'entrenament. A que es deu aquest comportament? Compareu el resultats obtinguts amb els vostres companys. En que és diferencien? Per què?
L'arbre de decisió entrenat també pot ser visualitzat. La funció export_graphviz de la llibreria d'arbres de sklearn permet generar un codi que després pot ser interpretat per un generador de gràfics jeràrquics com WebGraphViz.
from sklearn.tree import export_graphviz
print(export_graphviz(decision_tree_classifier, out_file=None))
Exercici 6: Feu servir el codi obtingut anteriorment i el visualitzador on-line de WebGraphViz per generar la visualització del vostre arbre de decisió.
Per tal d'aconseguir uns resultats més fiables, una de les solucions que podríem fer servir seria repetir l'experiment diverses vegades. La comanda de Python for X in Y: farà que tot el codi que estigui indentat per sota d'ella es repeteixi tantes vegades com elements existeixin a Y. Si ajuntem tot el codi generat fins ara i guardem els resultats, amb la funció de les llibreries de seaborn distplot() podrem veure un histograma dels resultats y la seva distribució.
resultats = []
# La comanda 'for' crea un bucle que es repetira tantes vegades com s'especifiqui
for repetition in range(1000):
# El primer que farems serà partir les dades
(entrades_train,
entrades_test,
classes_train,
classes_test) = train_test_split(entrades, classes, train_size=0.75)
# Crearem un arbre de decisió nou
decision_tree_classifier = DecisionTreeClassifier(criterion='entropy')
# Entrenem l'arbre
decision_tree_classifier.fit(entrades_train, classes_train)
# Calculem la seva precisió a l'hora de classificar
precisio = decision_tree_classifier.score(entrades_test, classes_test)
# Guardem el resultat
resultats.append(precisio)
seaborn.distplot(resultats)
plt.title('Precició mitjana: {}'.format(numpy.mean(resultats)))
Exercici 7: Compara els resultats amb els dels teus companys. Son resultats comparables? Raona la resposta.
Una de les pràctiques per obtenir resultats fiables és fer servir un sistema de validació creuada. La validació creuada consisteix en dividir totes les mostres en k subconjunts. Llavors, un dels k subconjunts es fa servir com a conjunt de proves mentre que els altres k-1 subconjunts s'uneixen per les entrades d'entrenament (veure Figura 3). Aquest procés es repeteix k vegades fins que tots els subconjunts s'han fet servir com a conjunt de proves. Finalment, els k resultats obtinguts s'uneixen fent servir una mitjana.
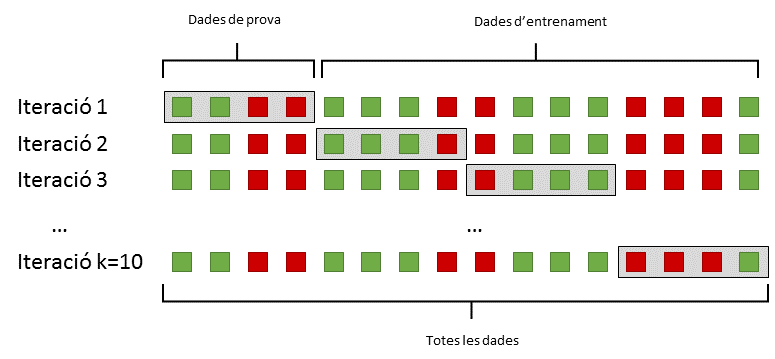 Figura 3: Divisió de les mostres originals mitjançant una validació creuada.
Figura 3: Divisió de les mostres originals mitjançant una validació creuada.
La validació creuada ja està implementada dins de les llibreries de sklearn amb la funció cross_val_score(). Aquesta funció requereix d'un model d'aprenentatge, totes les mostres d'entrada, les seves classes associades i la quantitat de subconjunts que crearà. Com a resultat, ens retornarà una llista amb la precisió de cada prova que podrem mostrar amb la funció distplot de seaborn.
from sklearn.model_selection import cross_val_score
# Inicialitzem un arbre de decisio nou per entrenar
decision_tree_classifier = DecisionTreeClassifier(criterion='entropy')
# Executem la validació creuada
puntuacio_validacio_creuada = cross_val_score(decision_tree_classifier, entrades, classes, cv=10)
# Mostrem la gràfica
seaborn.distplot(puntuacio_validacio_creuada)
plt.title('Precició mitjana: {}'.format(numpy.mean(puntuacio_validacio_creuada)))
Exercici 8: Com és el resultat ara? Si executes la cel·la varies vegades com canvia el resultat? Compara aquests resultats amb els obtinguts anteriorment.
Què cal lliurar¶
Document PDF amb els resultats i respostes d'aquesta llibreta.